Command Line Interface Intro:
Part 6
by Peter Kelly (critter)
Globbing
What? It's an unusual word that has it's roots in the way command line interpreters used to handle things in the early days of Unix.
The bash shell recognizes certain characters as 'wild cards' that can be used to specify unknown or multiple occurrences of characters when specifying file names. We've already met some of these 'wild card' characters back in chapter 3, '*' and '?'. These are the most common ones, but groups and classes of characters can also be used. When the shell encounters these 'wild cards' in a file name, it substitutes the meaning of the wild card at that position, a process known variously as "file name expansion", "path name expansion", "shell expansion" or "globbing", depending on how pedantic or geeky you want to be.
The following can be used:
- *
- means match at this position any one or more characters
- ?
- means match at this position exactly one character
Individual characters can be grouped in square brackets.
- [a,f]
- matches either a or f
- [a-m,w-z]
- matches only a character in the ranges a-m or w-z
- [a-z,0-9]
- matches any lowercase letter or any digit
- [!a-c]
- matches any character that is not in the range a-c
- [^a-c]
- same as above
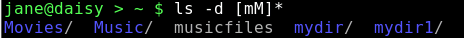
Another way of specifying groups of characters is to use pre-defined classes. These are groups of characters defined in the POSIX standard and the syntax is [:class:].
The defined classes include:
- [:alnum:]
- any alphanumeric character [0-9,a-z,A-Z]
- [:alpha:]
- alphabetical characters [a-z,A-Z]
- [:blank:]
- characters that don't print anything like spaces and tabs (also known as whitespace)
- [:digit:]
- numeric digits [0-9]
- [:punct:]
- punctuation characters
- [:lower:]
- lowercase characters [a-z]
- [:upper:]
- uppercase characters [A-Z]
- [:xdigit:]
- any character that may form a part of a hexadecimal number [0-9,a-f,A-F]
So, ls -d [[:upper:]]* will find all files and directories that start with an uppercase letter.
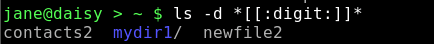
Note that two pairs of square braces are required here, one pair to define the start and end of a range and one pair to contain the class.
All of these methods may be combined to provide the file set that exactly matches your requirements. This method of file name expansion may reduce or increase the number of files to which your commands are applied.
The dot character '.' is not included in these expansions. Type ls -al in your home directory and you will see quite a few files that begin with this character. These are so called hidden files which is why we needed the -a option to the ls command to display them. The first two file names (in any directory) are the names of directories, '.' and '..', and these refer respectively to this directory and to the parent of this directory. Why do we need these? One reason is to be able to refer to a directory without specifying its name.
- cd ..
- takes you up a level
- cd ../..
- takes you up two levels and so on
If you write a script and want to execute it, then it has to be on your PATH (a list of directories to be searched for executable files), or you have to supply the full absolute address for the file. Typing ./myscript {this directory/myscript} is easier than /home/jane/myscripts/myscript.
For security reasons, it is inadvisable to add your home directory to your PATH.
If then, the dot character is not included in these expansions, how do we include hidden files if we want them to be a part of our list of files to operate on, but we don't want the two directory shortcuts '.' and '..'?
Suppose we want to rename all files in a directory with the extension '.bak', but some of these files are hidden 'dot' files? If we try to rename all files, including those beginning with a dot, then we will include . and .., which we didn't intend (you will probably get an error).
We could make two lists of files, one of normal files and one of dot files with the two unwanted files filtered out, or we could could get the shell to do our dirty work for us. The bash shell has a lot of options and is started by default with those options set that your distribution settled on as being most useful for everyday use.
For a list of those options that are set (on) type shopt -s. The shopt command is used to display the status of shell options. shopt -u lists those that are unset.
The one that we are looking for here is called dotglob.
Setting this option on expands the dots that signify a hidden file, but ignore the two directory shortcuts. shopt -s dotglob turns it on, while shopt -u dotglob turns it off again. Don't forget to do this or you will remain in unfamiliar territory.
To rename all of the files, we need to use a loop. I will explain the mechanism of this when we get to shell scripting — the real power of the shell. For now just follow along.
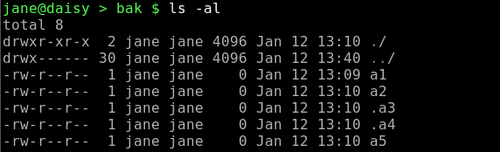
ls -al shows 2 unwanted directory shortcuts and 5 files, 2 of them hidden dot files.
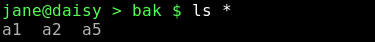
The '*' does not expand to show the hidden dot files or the directory shortcuts.
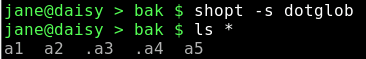
By turning on the shell option dotglob, the wild card '*' expands into all of the files but ignores the directory shortcuts.
We now can run our loop, and a check reveals that all files have been renamed:
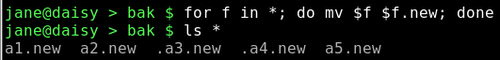
Turning off the option reverts to the normal mode of dot files being unexpanded.

The bash shell expansion is not limited to file names. There are six levels of expansion recognized by bash. They are, in alphabetical order:
- Arithmetic expansion.
- Brace expansion.
- File name expansion.
- History expansion
- Shell parameter expansion.
- Tilde expansion.
If you are not at least aware of these, then you may find yourself inadvertently using them and then wondering why you are getting such weird results.
Arithmetic expansion. The shell can do limited integer-only arithmetic, its operators all have have different meanings under different circumstances in the shell. They are:
- +
- Addition
- -
- Subtraction
- *
- Multiplication
- /
- Division
- **
- Exponentiation
(The exponentiation operator is more usually '^'. However, this is used for negation in the shell expansion rules.) - %
- Modulo (remainder)
The syntax is $((expression)). Again, note the two sets of braces. Expressions may be nested within the first pair of braces and standard operator precedence is observed. Whitespace (e.g., spaces and tabs) has no meaning within the expression.
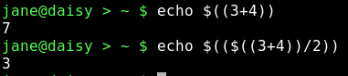
3 + 4 = 7
7 / 2 = 3 Integers only!
Tilde expansion. we may as well get this one out of the way now as the only way we are likely to use it is very simple.
We can use the tilde '~' as a shorthand way of referring to our home directory by using it as the first letter of an expression.
cd ~ change to our home directory
cd ~/mydir1 change to the sub-directory mydir in my home directory.
If we follow the tilde with the login name of another user then the command is relative to that users home directory. cd ~john change to johns home directory. No forward slash is required between the tilde and the users login name but you obviously still need the correct permissions to enter the directory if you are not the owner or a member of the directories group.
So is that all there is to tilde expansion. Of course not, this is Linux!
A system administrator might use it to assign expansions to commands by manipulating the directory stack — but you really didn't want to hear that did you?
Brace expansion is particularly good for a situation where a sequence of files or directories need to be created or listed.
The syntax is {a,b,c} or {A..J} or {1..8}.
For example, to create a set of directories to hold a years notes
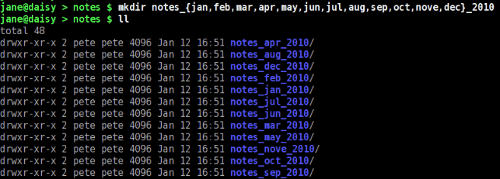
You can use brace expansion wherever you need to put a set of items into a common expression.
History expansion. When you type the command history, you are presented with a numbered list of previously typed commands. Entering !number (where number is the number in the list) executes that command, this is history expansion at work. There is more to it than that, but it shouldn't bother us for the moment.
Shell parameter expansion is at its most powerful when used in shell scripts, but in its simplest form, it takes whatever follows a '$' and expands it into its fullest form. What follows the $ is often an environment variable, which may optionally be enclosed in braces i.e. ${var}, but it can be much more.
Environment variables are names given to things that need to be remembered in your current working environment. An example of this is where you currently are in the file system. To find this out you might issue the command pwd. This information is stored in the environment variable named
PWD (uppercase is customary and does help to distinguish variables from other text. Whatever the case of the name you will have to use it as Linux is case sensitive).
Typing the command echo $PWD uses parameter expansion to the expand the variable name PWD to the full path of your current directory before passing it to the command echo.
To see a list of environment variables and their contents that are currently set up in your environment, type the command env.
Some you will recognize, and you can always add your own by use of the export command in your .bashrc file.
export SCRIPTS_DIR="/home/jane/scripts"
After that, the command cp my_new_script $SCRIPTS_DIR will make sure that it goes to the correct place, providing of course that it exists..
With all these different ways that the shell can interpret what you type, we need some method of controlling what gets seen, as what and when. After all, although the bash shell is very powerful, we do want to be remain in control.
Control of shell expansion is exercised through the use of quotes. In Linux you will find four different kinds of quotes in use
- “ ”
- The decorative 66 — 99 style used in word processors — these are of no interest to us.
- "
- Standard double quotes
- '
- Single quotes
- `
- Back ticks, also known as the grave accent
The last three all produce different results in the bash shell.
Double quotes tell the shell to ignore the special meaning of any characters encountered between them and to treat them exactly literally, with the exception of $, ` and \. This is useful if we want to pass the shell a file name containing an unusual character or space. However, because the $ is still interpreted, variables and arithmetic will still be expanded. But after expansion, everything between the quotes will be passed to the command as a single word with every character and all white space intact. The interpretation of the back tick you will see in a moment, just remember that here it is preserved. The backslash allows us to escape the $ or ` so that we may pass expressions such as "You owe me \$100".

See the difference?
Single quotes are the strongest form of quoting and suppress all expansion. Whatever you put between these gets passed on verbatim. No changes whatsoever.
Back ticks evaluate and execute the contents and then pass the result to the command.
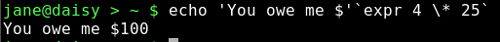
Here 'You owe me $' is passed literally as it is enclosed in single quotes. The next part, `expr 4 \* 25`, evaluates the expression 4 * 25 to be 100 before passing it to the echo command. The backslash is needed before the asterisk to escape its alternative meaning as a wild card.
All of this globbing and wild card stuff should not be confused with regular expressions (often abbreviated to regexp), even though they do share some common features.
regular expressions are used to manipulate and scan data for a particular pattern and is something much bigger.
You've already used regular expressions when we used the grep command. The command grep (global regular expression print, from the original line editor ed which used the command g/re/p! to achieve the same thing.) has two brothers known as egrep and fgrep (there's another brother known as rgrep but we don't see much of him).
We use the grep command to find a matching pattern of characters in a file, set of files or in a stream of data passed to the command. The general syntax is grep {options} {pattern} {files}.
It can be used directly as a command, or used as a filter to the output from some other command.
To find janes entry in the /etc/passwd file we could use either grep jane /etc/passwd or cat /etc/passwd | grep jane

In the above examples, jane is a pattern that grep tries to match.
Regular expressions are sequences of characters that the software uses to find a particular pattern in a particular position within the target data.
Why bother with regular expressions at all?
Linux uses plain text files for most of its configuration, for the output from commands and scripts and for reporting on system activity, security and potential problems. That's an awful lot of text, and to be able to search accurately for some particular information is one of the most important skills a command line user can master.
To use regular expressions we use three main tools:
grep is used to search for a pattern
sed is a stream editor used to filter and manipulate data streams. This enables us to pass pre-processed data directly on to the next command, to a file or to stdout/stderr.
awk is a scripting/programming language used to automate pattern searches and data processing.
Many other commands, such as tr (translate), use regular expressions, but if you can get a grip on these three tools, then you are on your way to a higher level of command line usage.
Before we go on to discuss grep and sed (I'll leave awk until we have done some programming in the bash scripting section), we need a good basic understanding of regular expressions. Regular expressions are used by line based commands and will not match patterns spread over two or more lines. I just thought that you ought to know that.
In regular expressions certain characters have a special meaning and these are known as meta characters. For any meta character to be taken literally, and to lose its special meaning, it has to 'escaped', usually by preceding it with a backslash character, as we have done previously with wild card characters. The following are meta characters, but not all are recognized by all applications.
- .
- The dot character matches any single characters
- *
- The asterisk matches zero or more occurrences of the preceding character.
- ^
- The caret is a tricky one, it has two meanings. Outside of square brackets, it means match the pattern only when it occurs at the beginning of the line, and this is known as an anchor mark. As the first character inside a pair of brackets it negates the match i.e. match anything except what follows.
- $
- Another anchor mark this time meaning to only match the pattern at the end of a line.
- \< \>
- More anchor marks. They match a pattern at the beginning \< or the end \> of a word.
- \
- The backslash is known as the escape or quoting character and is used to remove the special meaning of the character that immediately follows it.
- [ ]
- Brackets are used to hold groups, ranges and classes of characters. Here a group can be an individual character.
- \{n\}
- Match n occurrences of the preceding character or regular expression. Note that n may be a single number \{2\}, a range \{2,4\} or a minimum number \{2,\} meaning at least two occurrences.
- \( \)
- Any matched text between \( and \) is stored in a special temporary buffer. Up to nine such sequences can be saved and then later inserted using the commands \1 to \9. An example will make this clearer.
- +
- Match at least one instance of the preceding character/regexp. This is an extended regexp (ERE) — see later.
- ?
- Match zero or more instances of the preceding character/regexp. This is an extended regexp (ERE) — see later.
- |
- Match the preceding or following character/regexp. This is an extended regexp (ERE) — see later.
- ( )
- Used for grouping regular expressions in complex statements
With these we can find just about any pattern at any position of a line. Some of these meta characters do take on a different meaning when used to replace patterns.
grep
First off egrep is exactly the same as grep -E and fgrep is exactly the same as grep -F so whats the difference?
fgrep uses fixed strings to match patterns, no regular expressions at all, and so it does actually work faster.
egrep is actually a more complete version of grep. There are two sets of meta characters recognized by regular expressions, known as BRE and ERE, or Basic regular expressions and Extended regular expressions. BRE is a subset of ERE. BRE is used by grep, and egrep uses ERE. BRE does not recognize the meta characters + ? and |, and requires the ( ) { } meta characters to be escaped with a backslash. For now, we'll stick to plain old grep. Just to set the record straight, rgrep, the other brother, is just grep that will re-curse down through directories to find a pattern match.
The grep command comes with a set of options that would make any Linux command proud. Here I'll go only through those options that normal people might use.
- -A, -B & -C
- followed by a number, print that number of lines of context After, Before or around the match — this helps to recognize things in a long text file.
- -c
- Only output a count of the number of occurrences of a match for each file scanned.
- -E
- Use the extended set of regular expressions (ERE). The same as using the command egrep.
- -F
- Don't use regular expressions — treat all pattern characters literally. The same as fgrep.
- -f filename
- Use each line of the named file as a pattern to match.
- -h
- Don't output the filename when searching multiple files.
- -i
- Ignore case
- -n
- Output the line numbers of lines containing a match.
- -r
- Recurse through sub-directories.
- -s
- Suppress error messages
- -v
- Invert the match to select only non-matching files
- -w
- Match only complete words. A word is a contiguous block of letters, numbers and underscores.
That's enough theory for now, so let's go visit the family grep and do a few examples.
If we were unsure how jane spelled her name (jane or jayne), then to search for her name in the /etc/passwd file we may be tempted to use the '*' wild card with grep j*ne /etc/passwd but this would fail, as the shell would expand j*ne before passing it to grep, which uses regular expressions to match the search pattern.
We could use grep ja[n,y] /etc/passwd.

This would however also match names such as janet.
To get around this, we could use the extended set of regular expressions available with the -E option or the egrep command. grep -Ew 'jane|jayne' /etc/passwd match either jane or jayne. The -w option matches only complete words. The quotes are needed to prevent the shell expanding the vertical bar symbol into a pipe.

How many users have bash as their default shell?
grep -c '/bin/bash' /etc/passwd

To search for files in your home directory that contain a match, burrowing down through subdirectories and discarding warnings about inaccessible files, we could use a command such as grep -rs glenn ~/*

Multiple use of the grep command can simplify complex searches. To search for directories that begin with an uppercase or lowercase 'm', use ls -l | grep ^\d | grep [M,m]. This matches all lines output from a long directory listing that begin with a 'd' (i.e., are directories). The output from this is then piped through another grep command to get the final result.
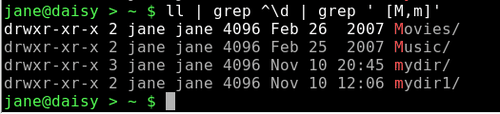
As you can see from the examples, grep is a powerful tool to find the information that you want from files or from a commands output. It is especially useful if you don't know where that information is, or even whether it exists at all, in the places that you are looking.
Sometimes you know exactly what information is available but you want only certain parts of it. Linux has a command that will help you to get exactly what you want.
cut
The cut command is only really useful when you have tabulated data but as so many commands output data in that format it is a tool that is really worth knowing about and it is really simple to use.
When you examine a file of tabulated data, you'll see groups of characters separated by a common character, often a space, comma or colon. This common character is known as a delimiter, and the groups of characters are known as fields. The cut command searches each line of text looking for the delimiter, and numbering the fields as it does so. When it reaches the end of the line, it outputs only those fields that have been requested. The general form of the cut command is:
cut {options}{file}
The most useful options are:
- -c list
- Select only characters in these positions
- -d
- Specify the delimiter. If omitted, the default is tab. Spaces need to be quoted -d" "
- -f list
- Select the following fields
- -s
- Suppress lines without delimiters
List is a sequence of numbers separated by a comma or, To specify a range, by a hyphen.
If we look at a line of data from the /etc/passwd file, we will notice that the various 'fields' are delimited by a colon :.
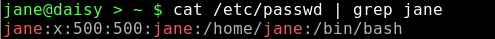
The first field contains the users login name and the fifth field, known for historical reasons as the gecos field (from General Electric Comprehensive Operating System), and contains the users real name and sometimes some optional location information, although PCLinuxOS doesn't use this additional information.
To extract the users login names and real names we use the command like this: cut -d: -f1,5 /etc/passwd.
This tells the command to look for a colon as a delimiter and to output fields 1 and 5.
All of this is fine for nicely ordered data as we find in the /etc/passwd file, but in the real world things don't always work out like that. Take for example the ls -l command. This outputs a nicely formatted long directory listing. The catch here is that to make the output look nice and neat, the ls command pads the output with extra spaces. When our cut command scans the line using a space as the delimiter it increases the field count each time it encounters a space and the output is, at best, unpredictable. Many Linux commands pad their output in this way. The ps commands output is another example of this.
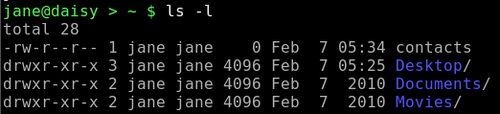
If I wanted to extract the owner, size and file names from this listing it would be reasonable to assume that I needed fields 3,5 & 9 and that the delimiter is a space.
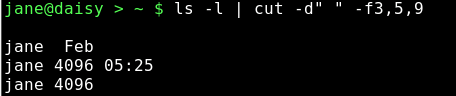
As you can see, the output is not as expected. We could try the -c option, ignoring fields and counting the characters from the start of the line.
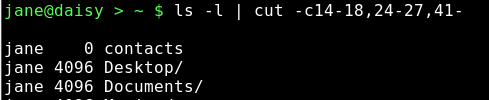
But apart from being tedious and error prone, if the directory listing changes slightly then the numbers will be different and the code is not re-usable, we would have to start over.
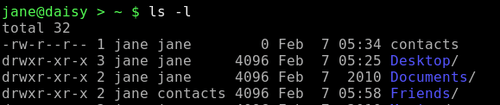
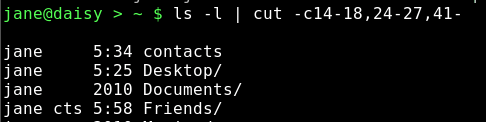
To work around this, we need to prepare the output from the ls command by filtering out the extra spaces. We can do this by using a command we have met once before. The tr command translates data, and we used it previously to change text from lowercase to uppercase. If we use the tr command with the -s option followed by a space, it sqeezes repeated spaces out of the file or data stream that we feed it.
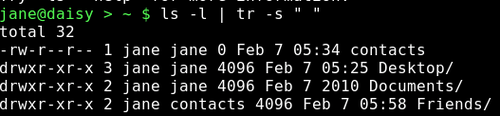
We can now cut out exactly the data the we want.
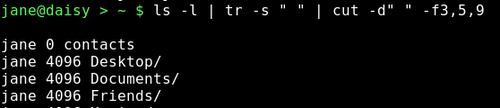
Two other commands, rather simple but occasionally useful, so worth mentioning, are paste and join. Typing the command name followed by --help will give you enough information to use these commands, but a simple example may better show their usefulness and their differences.
Suppose we have two files containing different data about common things such as these:
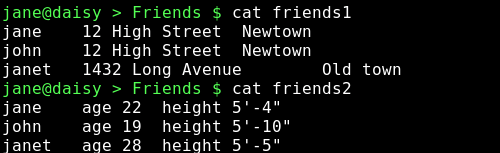

The names in these files are common but the data is different. We can merge the data from both files with join.
With paste we can add data we cut from one file to the end of another file on a line by line basis

sort
When you have found the data that you want, cut out all but the required information, and joined or pasted the results, it may not be in the order that you want. Here, Linux has an exceptionally powerful & quick utility to do just that.
The syntax of the sort command is sort {options} {file(s)}. If more than one file is supplied then the combined contents of the files will be sorted and output.
The options available for the sort command make for a rather comprehensive utility. These are the most useful ones:
- -b
- Ignore leading blanks in the sort field
- -c
- Only check whether the data is sorted but do not sort
- -d
- Sort in dictionary order, consider only blanks and alphanumeric characters
- -f
- Treat upper and lowercase as equal
- -i
- Consider only printable characters. This is ignored if the -d option is specified.
- -k
- Specify the sort field
- -n
- Numeric sort
- -r
- Reverse the sort order
- -t
- Specify the field separator
- -u
- Output only the first of one or more equal lines. If the -c option is specified, check that no lines are equal
A couple of these options need further explanation.
sort doesn't have the hangups about field delimiters that commands like cut have. Fields, as far as sort is concerned, are separated by the blank space between them, even if these blank spaces contain multiple non-printing characters. This is generally a good idea, but occasions arise when this causes problems, as in /etc/passwd, which has no blank spaces. In these cases, the field separator can be specified with the -t option. Sort -t: -k5 /etc/passwd would sort the file on the 5th (users real name), using the colon to decide where fields start and end.
Specifying the sort field used to be a strange affair, but with the -k option it is now reasonably straight forward.
-k {number} Specifies the field in position {number}.
Numbering starts at 1. More complex sort field arguments may be specified, such as which character within the sort field to start or end sorting on. I like to take a 'learn it if you need it' approach to these things, as I find that I rarely need such features and I don't like to clutter my poor brain unnecessarily.
ls -l | sort -k9 Sorts a directory listing in dictionary order on the 9th field (file name).
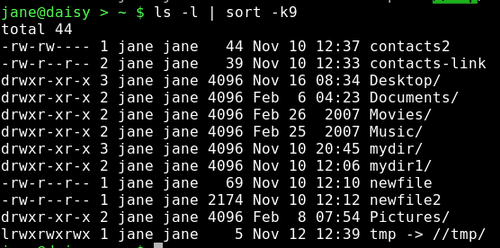
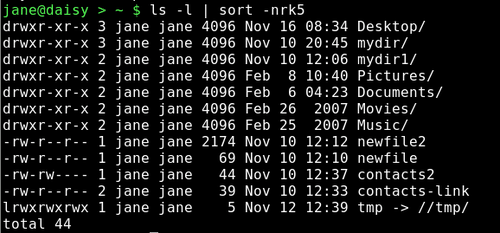
ls -l | sort -nrk5 Sorts the listing by the 5th field ( file size ) in reverse numerical order.
An awful lot can be done with these few commands and a little practice. If you want to do more, then of course you can. This is where the sed stream editor excels, enabling search and replace, insertion, deletion, substitution and translation to multiple files at the same time if that is what you want. sed can be a simple substitution tool or as complex as you like. We'll be meeting sed very soon.



