Command Line Interface Intro:
Part 9
by Peter Kelly (critter)
Almost everything that you do on the command line involves moving, changing, comparing or deleting text data. This data may reside in a file on a disk drive or be generated as the output from a previous command in the form of a data stream.
When the UNIX operating system was first developed at Bell Laboratories in the early 1970's, Ken Thompson, who is generally regarded as the chief architect of the project, was keen to implement a system of inter-connecting streams of data as an alternative to using a series of discrete processes to achieve the required output. Today we refer to this system as 'pipes' and 'redirection'.
The software tools available in those dark days were rather primitive, but have mostly survived and evolved into what we use today. The program ed has survived mostly unchanged in its usage since those times (which probably accounts for its lack of use today). ed is a line editor, unlike text editors such as vi(m). A line editor reads in a file and works on one line at a time, not on the whole file. You make changes to the line and then move to another line.
Just as the program was simple, and so were the commands. You used p to print the line to the terminal so that you can actually see what you are editing (this is not done automatically), d to delete the line, s to substitute some text for some other text, but only in that line. To edit a large text file interactively, by hand, this is far too restrictive. So the text editors that we more commonly use today were developed.
With the introduction of pipes for streams of data through this method of editing line by line, non-interactively is ideal and so a new tool was introduced known as a stream editor. This reads in data and applies a series of commands to the data as it flows through. These commands, deletions, substitutions etc, could be supplied on the command line, or read in from a file or script. If the input data is from a file, then that file is not changed. Only the data in the output stream is affected, and this can be saved as a new file or further processed along the 'pipeline'.
As a model for this new tool the ed editor was chosen and named sed — stream editor, which you may have heard of.
SED
The sed utility retains a lot of the simplicity of commands it inherited from ed, but it adds a lot more functionality. Its command line or script can be a bewildering gibberish text when you first encounter it.
sed -n -e 's/M/ MegaBytes/;s/-.\{12\}\(.\.. MegaBytes\) \([0-9]\{4\}\)-\([0-9][0-9]\)-\([0-9][0-9]\) ..:.. \(.*$\)/\4\/\3\/\2 \1 \5/p' sed-demo
If we break down this gibberish into manageable phrases, then it becomes more comprehensible. It really does, trust me. Now before you throw your hands in the air and say "This is not for me!" let me say that it is very unlikely that you would ever need to construct such a complicated command.
Here's something a lot simpler and is actually useful. Many Linux users also use MS Windows, but if you try to read a Linux created text file in Windows, then you find that the line breaks don't work and extend to the full width allowed by the editor, probably notepad. This is because Linux terminates its lines with a newline character \n, while DOS and Windows need a newline and a carriage return pair \n\r (just like the old typewriters, where you move the paper up a line and push the carriage back to the beginning of the line). A newline on its own is not recognized as a line termination. Sed makes light work of this.
sed 's/$/\r/' linux-file > dos-file makes Linux files DOS-readable.
sed 's/\r//' /dos-file > linux-file converts them back, although this usually isn't necessary as Linux will disregard the extra carriage returns.
It would be a trivial matter to put these two files in a script and create a couple of aliases to them, perhaps l2d and d2l.
The syntax of sed is very simple:
sed {options} {commands} {file}
options
The most useful options available for GNU sed, which is the version that Linux users will most likely find that they have installed, are:
-e is required when you are specifying commands on the command line and tells the application that what follows should be treated as a command to be applied to the current line. The option can be repeated on the command line to apply multiple commands to the input data.
-n silent mode, don't automatically print the lines to stdout.
-f script add the contents of the named script to the commands to be executed
-r use the extended set of regular expressions (like egrep)
--posix disable gnu extensions. This makes scripts portable to systems that have the standard unix-like version of sed
--help covers all the options for the version that you are using.
commands
These define what you do to the data as the stream passes through, and I will describe the use of the most important ones in the body of this text.
file
This is the input data stream, and if the file name is supplied on the command line, it is treated as stdin. That is, sed command file and sed command < file mean the same thing. The input may also be piped in to the command, e.g. cat file | sed command or ls -l | sed command.
To get started, find or create a file to play around with. I have used a short listing of my /boot directory, in a file named sed-demo, ls -AlLGgh /boot >sed-demo, which looks like this:
total 31M -rw-rw-r-- 1 440 2010-04-02 10:59 boot.backup.sda -rw-r--r-- 1 111K 2010-04-03 15:11 config -rw-r--r-- 1 108K 2010-03-16 15:11 config-2.6.32.10-pclos2.pae -rw-r--r-- 1 111K 2010-04-03 15:11 config-2.6.33.2-pclos1.pae -rwxr-xr-x 1 579K 2010-04-02 10:59 gfxmenu* drwxr-xr-x 2 4.0K 2010-04-05 04:11 grub/ -rw------- 1 6.4M 2010-04-02 11:35 initrd-2.6.32.10-pclos2.pae.img -rw------- 1 6.4M 2010-04-04 08:56 initrd-2.6.33.2-pclos1.pae.img -rw------- 1 6.4M 2010-04-04 08:56 initrd.img -rw-r--r-- 1 1.5K 2010-04-10 14:04 kernel.h -rw-r--r-- 1 1.5K 2010-04-02 11:59 kernel.h-2.6.32.10-pclos2.pae -rw-r--r-- 1 1.5K 2010-04-10 14:04 kernel.h-2.6.33.2-pclos1.pae -rw-r--r-- 1 249K 2006-11-05 23:23 message-graphic -rw-r--r-- 1 1.4M 2010-04-03 15:11 System.map -rw-r--r-- 1 1.4M 2010-03-16 15:11 System.map-2.6.32.10-pclos2.pae -rw-r--r-- 1 1.4M 2010-04-03 15:11 System.map-2.6.33.2-pclos1.pae -rw-rw-r-- 1 256 2010-04-02 10:59 uk-latin1.klt -rw-r--r-- 1 2.0M 2010-04-03 15:11 vmlinuz -rw-r--r-- 1 2.0M 2010-03-16 15:11 vmlinuz-2.6.32.10-pclos2.pae -rw-r--r-- 1 2.0M 2010-04-03 15:11 vmlinuz-2.6.33.2-pclos1.pae
This file contains a mixture of lines of varying length, and fields of differing construction. To select only data that meets certain criteria, and to re-format parts of it to more accurately meet my requirements, would be very difficult without a utility like sed.
The changes I want to make to this set of data are:
- Remove the total count
- Keep only regular files, no links,directories etc.
- Remove the permissions fields
- Remove the link counts
- Keep only lines that contain files of 1MB or larger
- Change 'M' to 'MegaBytes'
- Change the date format from year-month-day to day/month/year
- Remove the time field
- Output the date size and file name — in that order.
Now that looks like a lot of work, but thanks to the flexibility of sed, I can do it in one command.
To get rid of the line 'total 31M' and leave only the lines with file details, I could issue the following command:
sed -e '/total/d' sed-demo
This is the beginning of the output from this command.

The line at the start of the listing that contained the expression total has disappeared from the output.
So what did I do here? I issued the sed command with the -e option, which told sed to treat the next command line argument, '/total/d', as a command to apply to the input file sed-demo.
What seddid was to read in the entire sed-demo file line by line into an area of memory known as pattern space and examined each line to see if it could match the regular expression total, which is surrounded by a pair of slashes. Whenever a match was found, sed applied the d command, which deletes the current line from pattern space. This results in no output from sedfrom the analysis of that line. Lines that do not contain a pattern match are unaffected and flow through the command to stdout, which in this case is the terminal, as output has not been redirected elsewhere.
While that simple example of sed usage is not difficult to follow, the key phrase here is 'regular expression,' and a good understanding of regular expressions is required to make effective use of this command.
We covered the basics of regular expressions when we discussed the grep command, so perhaps a refresher is in order.
A regular expression is a sequence of literal characters and meta-characters. Literal characters are treated exactly as they are written and are case sensitive. Meta-characters have a special meaning in regular expressions, and must be expanded to produce the search pattern from the regular expression. These are the basic meta-characters:
- .
- The dot character matches any single character.
- *
- The asterisk matches zero or more occurrences of the preceding character. This is not the same behavior as the shell wild-card character.
- ^
- The caret is a tricky one, it has two meanings. Outside of square brackets it means match the pattern only when it occurs at the beginning of the line, this is known as an anchor mark. As the first character inside a pair of brackets it negates the match i.e. match anything except what follows.
- $
- Another anchor mark this time meaning to only match the pattern at the end of a line.
- \< \>
- More anchor marks. They match a pattern at the beginning \< or the end \> of a word.
- \
- The backslash is known as the escape or quoting character and is used to remove the special meaning of the character that immediately follows it.
- [ ]
- Brackets are used to hold groups, ranges and classes of characters. Here a group can be an individual character.
- \{n\}
- Match n occurrences of the preceding character or regular expression. Note that n may be a single number \{2\}, a range \{2,4\} or a minimum number \{2,\} meaning at least two occurrences.
- \( \)
- Any matched text between \( and \) is stored in a special temporary buffer. Up to nine such sequences can be saved and then later inserted using the commands \1 to \9.
In the previous example, the regular expression we used, total, contained only literal characters. But more usually, you will build up a regular expression from literals, meta-characters and character classes such as [:digit::] or [:space:]. The use of meta characters in regular expressions enables you to very quickly match quite complicated or unknown patterns. Some examples:
sed -e '/^#'d' .bashrc Would strip out any comments from your .bashrc file as comments begin with a #.
sed -e '/^$/d' .bashrc would remove any blank lines by matching the beginning and end of the line with nothing in between.
It is quite safe to try these out since the source file is not altered. Only the output to the terminal is changed.
In my test file, I have one directory, /grub, and this is denoted by the letter d at the beginning of the line. To remove the line, we can use sed's delete command with a regular expression that matches only that line.
sed -e '/^d/d' sed-demo matches all lines beginning, that's the ^, with d, and applies the delete command. The command is single quoted to prevent shell expansion of meta characters. Recall that single quotes are known as strong quotes, and protect the contents from the effects of shell expansion, which wouldn't have had any effect here, but it is a good habit to get into.
To keep directories and remove all other lines, we need to reverse the effect of the command, which we can do with:
sed -n -e '/^d/p' sed-demo
The -n turns off automatic echoing of pattern space to the terminal, and the p command, on finding a pattern match, prints the current contents of pattern space to stdout which, as the output has not been re-directed, is the terminal.
Alternatively we could look for lines that begin with a hyphen, and that would also exclude anything that wasn't a regular file.
sed -n -e '/^-/p' sed-demo
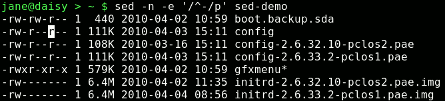
The directory line has been removed but so has the total line as that also did not begin with a hyphen. In this case it helps, but we have to be extremely careful about what we want to include or exclude. Similarly, we can remove all lines that do not contain an uppercase M followed by a space to keep only files of one MB or larger. Without the space, the total line would be included, as that also contains an uppercase M but no trailing space.
sed -n -e '/M /p' sed-demo
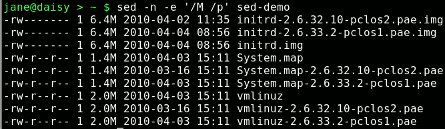
In the first example, I matched the pattern total to remove the first line, but I could more easily have specified an address.
sed -e '1d' sed-demo the 1 is the line number that I want to remove. Addresses can be ranges, so sed -e '8,20d' will remove lines 8 to 20 from the output.
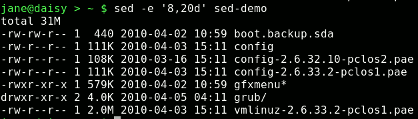
Notice that the total line and the directory line are still in the output, as the original data has not been altered.
In this case, I knew the address was 1, but usually you have to search for it. You do this by specifying a regular expression surrounded by slashes. The address of the line to delete in the first example was given by matching the regular expression /total/.
Substitution
Now that we have a means of keeping only those lines that we want in our final data set, we need to change some of that data. Probably the most used command for sed is s, to substitute one regular expression for another. The format for this is:
sed -e 's/old/new/' {file}
So that the command:
sed -e 's/M/ MegaBytes/' sed-demo
would change all the uppercase Ms to 'MegaBytes' (note the preceding space) in my test file. Note that sed by default only matches the first occurrence of the pattern on each line. If you need to match every occurrence, which is often what you want, then you have to add the g -global command:
sed -n -e 's/r/R/p' sed-demo would only replace the first r with R.
sed -n -e 's/r/R/gp' sed-demo replaces every occurrence.
Combining two commands we can make a substitution and output only the lines that we want to keep.
sed -n -e 's/M/ MegaBytes/' -e '/Mega/p' sed-demo
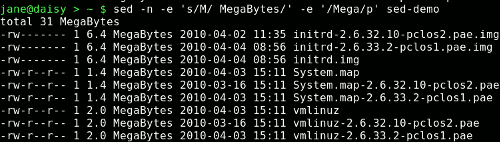
The substitute command can also be used to good effect to delete a part of the line. To remove the time field, we could match two characters followed by a colon followed by two characters and replace it with something like this:
sed -e 's/..:..//' sed-demo
To remove the permissions, the link count and trailing space at the start of the line, we could match a hyphen followed by exactly 12 characters by using the dot, \{ and \} metacharacters.
sed -e 's/-.\{12\}//' sed-demo
The dot matches any character, and the number inside the escaped braces tells the command how many matches to make. In other words, match exactly 12 characters.
One thing to be aware of when using regular expressions with meta characters is that they are greedy. They will always try to match the longest possible string.
If you try to remove the permissions with a command like this:
sed -n -e 's/-.*-//p' sed-demo
looking for a hyphen followed by some characters followed by a hyphen, then you might be disappointed to see that it matched strings like this:
-rw-r--r-- 1 111K 2010-04-03 15:11 config-2.6.33.2-
and output only
pclos1.pae.
Putting all this together makes for a pretty long command line, so I have used the shell line continuation character, the backslash, to make it more legible. But remember that it is all one line, as far as the shell is concerned.
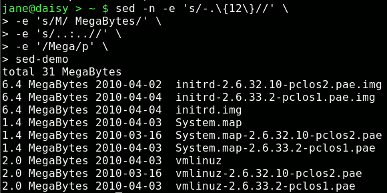
The skill in using sed is recognizing what you want to match, and the building of a regular expression that matches that part of the line, and only that part. This comes with practice and an understanding of regular expressions. Matching the file name is quite tricky, as there seems to be no 'standard format' that could be easily matched. So the easiest way out is to match everything else.
sed -e 's/-.\{34\}//' sed-demo
Here's the start of the output.
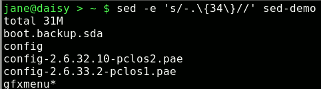
No, I didn't count all 34 characters. I took a guess, tried it and adjusted it. This trial and error method is quite common when building regular expressions, although not everyone admits it.
If you noticed that the total line is in the output, it is because it doesn't begin with a hyphen and we hadn't already removed it. The order of operation of your commands can have a great effect on the resultant output.
sed -e 's/[0-9]\{4\}-[0-9][0-9]-[0-9][0-9]//' sed-demo
matches the date part of the line and removes it. Here's how it works.
The first slash starts the search expression.
- [0-9]\{4\}
- matches exactly 4 digits.
- -
- matches a literal hyphen.
- [0-9][0-9]
- matches 2 digits.
- -
- matches a literal hyphen.
- [0-9][0-9]
- matches 2 digits.
- \4
- First \4 — the day
- \/
- followed by a forward slash that has to be escaped, or else we would terminate the substitution command
- \3
- followed by \3 — the month
- \/
- followed by a slash
- \2
- followed by \2 the year
- \1
- followed by a space and \1 — the size
- \5/p'
- and finally a space and \5 the file name, the substitution command terminating slash and the p command to print out the substituted data.
- sed-demo
- This is the name of the file that we want sed to process.
The second slash ends the search expression. When a match is found, it is replaced by whatever is between the second and third slash. In this case, nothing. For example, in the second line of the test file, 2010-04-02 is a match and will be removed.
Now we have most of the methods needed to complete the task, but the command line is getting rather clumsy. We could write a script and put all of the commands in there, but there is another way using the meta characters \( and \). Any thing that matches the regular expression that appears between this pair is is stored and can be recalled for later inclusion. A match from the first pair can be recalled with \1, the second pair with \2 and so on up to \9.
Here's the final command which turns off automatic line echoing, matches the entire line storing parts of it and then outputs some of those stored parts in the required order.
sed -n -e 's/M/ MegaBytes/' -e 's/-.\{12\}\(.\.. MegaBytes\) \([0-9]\{4\}\)-\([0-9][0-9]\)-\([0-9][0-9]\) ..:.. \(.*$\)/\4\/\3\/\2 \1 \5/p' sed-demo
Another way of writing this command without repeating the -e option is to separate the commands with a semicolon.
sed -n -e 's/M/ MegaBytes/';s/-.\{12\}\(.\.. MegaBytes\) \([0-9]\{4\}\)-\([0-9][0-9]\)-\([0-9][0-9]\) ..:.. \(.*$\)/\4\/\3\/\2 \1 \5/p' sed-demo
Personally, I find this harder to follow, but the choice is yours.
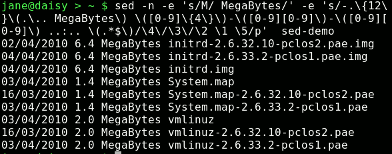
This is easier to follow if I break it down. Just to remind you, here's a typical line from the input file.
-rw-rw-r-- 1 440 2010-04-02 10:59 boot.backup.sda
sed -n -e 's/M/ MegaBytes/'
The first expression is a substitution replacing 'M' with a space, followed by the word MegaBytes.
-e 's/-.\{12\}
The second expression is also a substitution, replacing a hyphen, followed by exactly 12 characters.
\(.\.. MegaBytes\)
Followed by a character, a dot (which has to be escaped to retain its literal meaning), another character, a space, and the word 'MegaBytes'. All of the matching data is stored in \1. This is the size.
\([0-9]\{4\}\)
followed by exactly four digits, which are stored in \2. This is the Year.
-\([0-9][0-9]\)
followed by two digits, is stored in \3, and represents the month.
-\([0-9][0-9]\)
followed by two digits, is stored in \4, and represents the day.
..:..
followed by a space, two characters, a colon, two more characters and a space. This is the time, but as we don't use it, it isn't stored.
\(.*$\)/
followed by any number of characters that end the line, hence the dollar sign. This is the file name, and is stored in \5. This ends the search section of the substitution.
This is what we are going to replace the data we just matched with:
Easy peasy :)
Of course in real life, that is far too long a command to enter on the command line. Normally, such a complex operation would be written to a file and referenced by sed with the -f option.
With our commands in a file, we can easily test and adjust until we get the required result. We can also group multiple commands that you want to apply to the same address, or to each line, by placing them within braces. In the previous example we changed M to Megabytes, but more realistically, we might want to change M to MB and K to KB. If we create a file named sed-file (call it what you like) with the following text:
{
s/K/KB/
s/M/MB/
p
}
Then execute:
sed -n -f mysed-file sed-demo
As we haven't specified an address before the opening brace, all lines will be processed by applying both substitutions to each line, and then printing them to the terminal.
Lets try another test file. Here's a very simple html file that lends itself nicely to reconfiguration by sed. I've named it 2010.html. Don't worry if you don't know any html code. You only need to know that the things in the <> affect the look and format of the web page. <p> starts a paragraph and </p> ends it. These are known as tags.
<body> <h1>PCLinuxOS 2010 Release</h1> <p>Texstar recently anounced the release of the 2010 version of this popular distribution.</p> <h2>Now available in the following versions</h2> <p><li><em>KDE4</em> The base distribution</li></p> <p><li><em>Minime</em> Minimal KDE4 installation</li></p> <p><li><em>Gnome</em> Full installation of Gnome</li></p> <p><li><em>ZenMini</em> Minimal Gnome distribution</li></p> <p><li><em>LXDE</em> A lightweight desktop</li></p> <p><li><em>Phoenix</em> The XFCE desktop</li></p> <p><li><em>Enlightenment</em> The beautiful e17 desktop</li></p> <p><li><em>Openbox</em> Suitable for older hardware</li></p> </body>
This is how it appears in Firefox:

The emphasized or italic text is turned on and off by the <em> and </em> tags. To change this to bold, we need to replace the em with b.
To do that change only for the KDE based distributions, we need to supply a start and end address, and write the output to another file.
sed -e '/KDE4/,/Minime/s/em>/b>/g' 2010.html >2010b.html
The beginning address is the first match of KDE4, and the ending address Is the first match of Minime.

Voila! all done.
sed has three more commands that aren't used very much, and because of their unusual two line syntax, are best applied from a file. They are a — append, i — insert and c — change.
Our new html test file has one sub-heading, which is identified by the <h2></h2> pair. Normally, there would be many such headings, and possibly a folder of many html files. In such a case, the overall look of a website can be completely changed with a small sed script. Our little test file will suffice to show the operation of these commands.
If I create a file with this text and name it sed-file
/<h2>/{
i\
_________________________________________________
a\
_________________________________________________
}
And then issue the command:
sed -f sed-file 2010.html > 2010new.html
Then any line that has the <h2> tag (that's the address to which the group of commands between the braces will applied) will have a row of underscores inserted before it and appended after it.
The c command works in the same manner, changing any matching line or lines with the supplied text. If the address supplied covers a range of lines, then the entire block of text is replaced with a single copy of the new text.
In addition to the commands that I have covered here, sed has many more that would stretch us beyond an introductory text. There are flow control commands such as b — branch which enable scripts to loop under certain conditions, labels to which we can jump to perform certain operations dependent upon the outcome of a previous one, and is usually determined by the t — test command.
There are also a group of commands to manipulate an area of memory known as hold space. sed reads input lines into the area of memory known as pattern space and some, or all, of that data can be temporarily copied to hold space as a sort of scratch pad. sed can't operate on the contents of hold space. It can only add to it, read from it or swap one with the other. The commands are: g, G, h, H, x. They are known as get (from pattern space), hold (in pattern space) end exchange (swap). The uppercase versions append, and the lowercase versions overwrite the data.
The last command that I want to mention here is y which, in a not very intuitive way, means transform the characters in one string to the characters in another string by character position. The nth character in the first string is replaced by the nth character in the second string. As usual, an example shows this better.
To force a line to lowercase so that there will be no misunderstandings when the shell is interpreting a script:
sed 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/' myscript.sh