
| Previous
Page |
PCLinuxOS
Magazine |
PCLinuxOS |
Article List |
Disclaimer |
Next Page |
Get (Download) An Entire Website With wget |
|
by Paul Arnote (parnote) Have you ever wanted to save/preserve information you found online, but found it too difficult and time consuming to download each page? Or maybe you found it too tedious to print out each page, either on your printer or as a PDF file? Or maybe you needed to backup one of your own websites? Never fear, because wget can save the day. With wget, we can download an entire website, or just part of a website. I do have to admit that the "inspiration" for this article came from a 2008 Linux Journal article. CAUTION! Do NOT use this on a very large website, or a website with very large files! You will likely run out of storage space (or at least wonder where a very large chunk of it went). Plus, it's going to take some time to download all those files -- and even longer for the large files. Even a site like The PCLinuxOS Magazine website contains over 2 GiB of data and files. Also, do NOT keep "hammering away" at the same website, over and over again. You may cause unnecessary server traffic, minimally, and you may inhibit others from enjoying the same content. Some content should not be downloaded (e.g. password files, credit card information, etc.), and it's considered "poor ‘net citizenship" to access data and/or content that you normally wouldn't have access to. So, with those warnings out of the way, let's try to gain a basic understanding of wget and how to use it. Wget is a command line tool (ah, don't shy away if you're a GUI kind of guy or gal). If you type wget --help into a terminal session, the first thing you'll see is this: Usage: wget [OPTION]... [URL]... Then, that is followed by a few thousand (exaggerated) options. Without a doubt, wget has a LOT of options, which illustrates the power of wget. But all of those options are also a bit overwhelming for the new wget user. We won't cover everything you can do with wget in this article. More than anything else, this article is intended to introduce you to wget, and get you discovering how to use it. 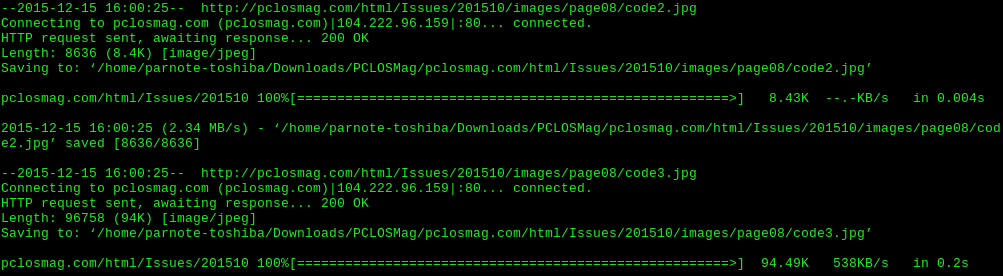 So, let's take a look at a wget command. We'll break it all down after you see the entire thing. The entire command is typed on one, single line. wget -x -r -np -k -v http://pclosmag.com/html/Issues/201511/ -P /home/parnote-toshiba/Downloads/PCLOSMag/ Let's dissect the command. Obviously, we start with the wget command. Next, the -x tells wget to force the creation of directories. The -r tells wget to recursively read all of the directories found under our starting point. Then, the -np option means "no parents," telling wget to not download the contents of directories higher in the directory hierarchy. Next, the -k tells wget to convert the links in the files to work on local storage. The -v turns on verbose output, which gives you a lot more information about the progress of the file downloads. Then, http://pclosmag.com/html/Issues/201511/ specifies the starting point for our download from the website, and corresponds to the directory on the website that contains the information we want to obtain. On the magazine website, each month's HTML files are in the /html/Issues directory, with each month's files in a subdirectory specified by the four-digit year and two-digit month. Thus, to download the HTML version of the December 2015 issue, you could change 201511 to 201512, and to download the HTML version of the March 2010 issue, you could change 201511 to 201003. Finally, the -P /home/parnote-toshiba/Downloads/PCLOSMag/ option tells wget where to save the files it downloads. In this case, it is in my /home directory (/home/parnote-toshiba), in the /Downloads directory, in the /PCLOSMag subdirectory. What you enter will depend on properly naming your /home directory, and the location you want to save the files you download. This command will download almost all of the files that make up the HTML version of the November 2015 issue of The PCLinuxOS Magazine to the directory you specify on your computer. There are files that aren't downloaded, such as the ads that appear in each issue. They reside in a different directory that has been labeled as "off limits" to bulk gathering programs. Those "off limits" directories are specified in the Robots.txt file that is on the magazine website. 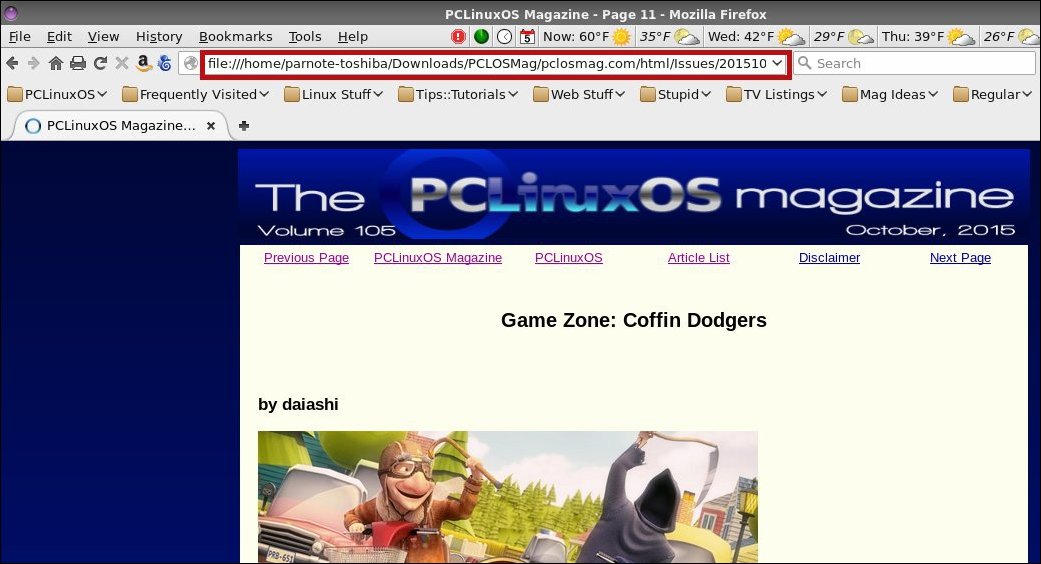 Notice the URL address line. Firefox is displaying the local file ... and all the links work, too! There are some wget command options that aren't compatible with one another. One is the -nc option, which stands for "no-clobber." It isn't compatible with the -k option, which converts all the links so that the offline files work as they should. The "no-clobber" option allows you to pick up where you left off, not overwriting files that have already been downloaded should you become disconnected before retrieving everything. Another is the -O option for specifying a filename for your download (yes, wget can also be used to download single files, too). Again, it isn't compatible with the -k option. I'm sure there are other incompatibilities that I haven't discovered yet. Of course, given all of the options available for wget, there are some other commands you might also be interested in. First, -D pclosmag.com would tell wget to not follow any links outside of the pclosmag.com domain. Second, -p, the short command for --page-requisites, tells wget to get all the images, CSS style sheets, scripts, etc. necessary to display the HTML page locally on your computer. Third, the -o option allows you to specify a log file for wget to write out to, instead of displaying the information in your terminal screen. Fourth, --user [username] and --password [password] (replacing [username] and [password] with your specific username and password) will pass along the specific field to the website, if you're on a site that requires a username and password. Finally, the -m option will mirror the entire website to your local computer, starting from your specified starting point. You'll be able to get everything except those directories that are marked as off-limits by the Robots.txt file. Wget is definitely a very handy tool to have in your online tool arsenal. I hope this introduction helps you begin to get a grasp and understanding of the immense power of wget. I urge you to explore some of the many other available options of wget. |






