
| Previous
Page |
PCLinuxOS
Magazine |
PCLinuxOS |
Article List |
Disclaimer |
Next Page |
DuckDuckGo Tracker Radar Exposes Hidden Tracking |
|
Reprinted from the DuckDuckGo Blog
In addition to shopping history, trackers can pick up your location history, search history, browsing history and more, and from those infer your age, ethnicity, gender, interests, and habits. Companies collate this personal data into a detailed profile, continually auctioning you off to the highest bidders. One of the best things you can do to protect yourself is to use a quality tracker blocker. While privacy protection is now important to a vast majority of people, our research on privacy behaviors finds only about 19% of people using tracker protection, and not necessarily of the highest quality. We are changing that! That's why we built seamless tracker protection into our DuckDuckGo Privacy Browser mobile apps (for iOS/Android) and into our DuckDuckGo Privacy Essentials desktop browser extensions (for Chrome/Firefox/Safari). They allow you to to seamlessly search and browse privately across all of your devices. They contain what we call the "privacy essentials" -- tracker blocking, private search, and upgraded website encryption -- all in one package. When we set out to add tracker protection, we found that existing lists of trackers were mostly manually curated, which meant they were often stale and never comprehensive. And, even worse, those lists sometimes break websites, which hinders mainstream adoption. So, over the last couple of years we built our own data set of trackers based on a crawling process that doesn't have these drawbacks. We call it DuckDuckGo Tracker Radar. It is automatically generated, constantly updated, and continually tested. Today we're proud to release DuckDuckGo Tracker Radar to the world, and are also open sourcing the code that generates it. This follows our recent release of our Smarter Encryption data and crawling code (that powers the upgraded website encryption component in our apps and extensions). Tracker Radar contains the most common cross-site trackers and includes detailed information about their tracking behavior, including prevalence, ownership, fingerprinting behavior, cookie behavior, privacy policy, rules for specific resources (with exceptions for site breakage), and performance data.
Too many people believe that you simply can't expect privacy on the Internet. We disagree and have made it our mission to set a new standard of trust online. We are publishing Tracker Radar and open-sourcing its code in furtherance of this mission. Below is more technical information about how we generate and maintain it. What is in DuckDuckGo Tracker Radar? Tracker Radar is actually two compendiums of information: 1. A file for each third-party domain (usually associated with tracking, but not always) containing detailed information about it. Each domain data file looks like this: 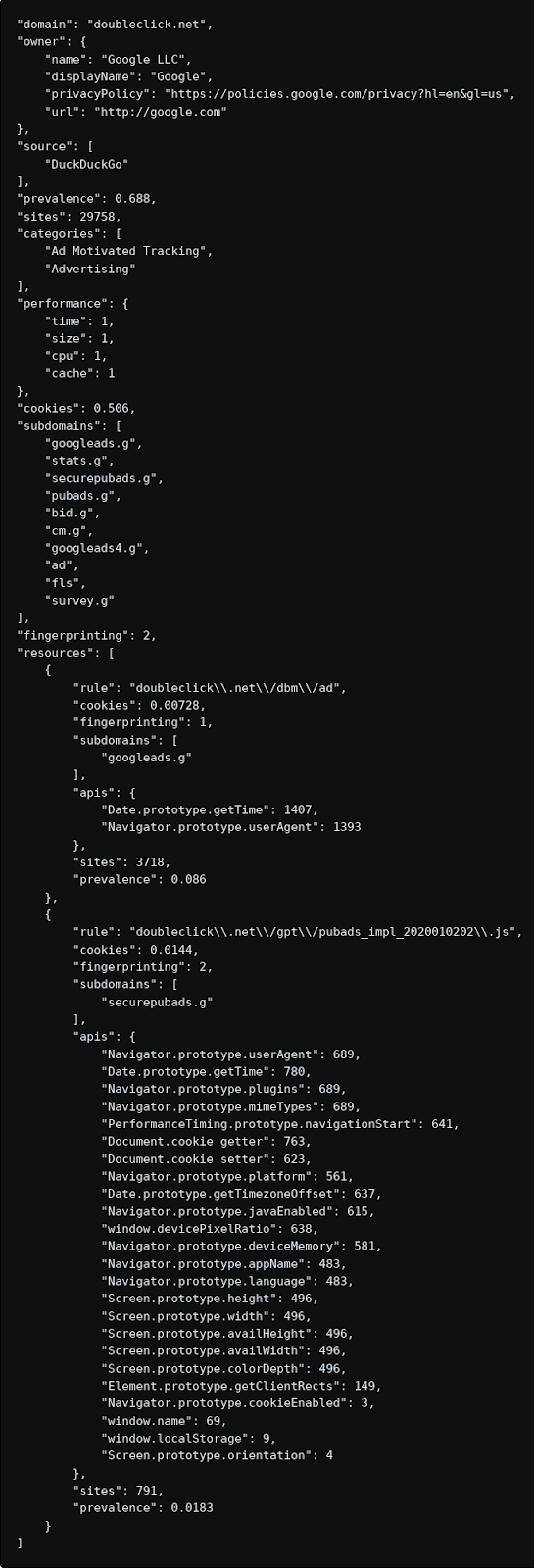
2. A file for each parent entity, associating it with domains. An entity data file looks like this: 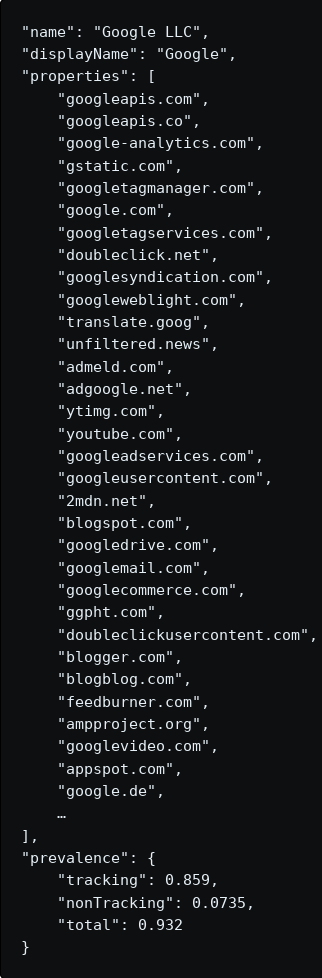 An entity file lists all the domains that an entity owns. These domains are found in our crawl and cross-referenced with domains and entity names found in WHOIS and SSL certificates. This list can be used to accurately determine when a tracker is being used in a third-party context. For example, we found doubleclick.net on 29,758 of the sites in our current survey (68%). Since it is owned by Google, which has 479 domains in our data set, this means doubleclick.net is being used on sites not owned by Google ~98% of the time. Taken together, Google-owned domains are referenced on 93.2% of the sites we surveyed. That is shown above as 'prevalence'. What can I do with Tracker Radar? There are three main things you can do: 1. For individuals, get a better tracker blocker. If you want the highest quality tracker protection derived from Tracker Radar, it is built into our DuckDuckGo Privacy Browser mobile apps (for iOS/Android) and our DuckDuckGo Privacy Essentials desktop browser extensions (for Chrome/Firefox/Safari). 2. For developers, make a custom tracker block list. You can use the information in the data set to generate your own tracker block list. While major browsers are making important strides to protect consumers from trackers, their current focus has been primarily on blocking trackers from setting cookies and limiting their access to browser resources commonly used for fingerprinting. However, they still don't block major trackers out right, which leaves the door open to many other types of tracking (e.g., exposing your IP address and recording your browsing history in the process). Tracker Radar can improve this situation because it identifies the trackers that can be totally blocked from loading at all without breaking websites. That's what we do with our tracker blocker in our app and extension, and we hope others will follow. As such, we would love to work with browsers to incorporate Tracker Radar as much as possible. 3. For researchers, study tracking. With all the detailed information in Tracker Radar, you can study web tracking more easily (and in the future, maybe other types of tracking). For example, the data set shows Google-owned trackers are on over 85% of the top 50K sites, Facebook on 36%: How does it compare to other tracker data?
In-browser tracker identification, using heuristics and machine learning. Crowd-sourced data is subject to the priorities and bias of the contributors. As a result, it's sometimes unclear why individual entries exist, their importance, whether they are still relevant, how to test them, and whether they break sites. In 2018, Brave performed a study of EasyList and found that "[more than] 90% of EasyList appears to provide little benefit for common browsing cases, due to its large size and accumulation of stale (rarely used or even expired) rules." Additionally, crowd-sourced block lists risk not being tested at scale, which can obscure many problems like the effect of adding a new rule, or rules that go stale as sites change. By contrast, we periodically crawl a large set of top websites so that we can be both comprehensive and up-to-date. Across the entire crawl, we look at how often a resource is used in a third-party context, how often it sets cookies, how it uses browser APIs, and how likely those APIs are used to identify individual users (fingerprinting). Looking at the full data set in this manner also makes it easier to discover new techniques. In-browser tracker identification can suffer from similar problems to crowd-sourced data -- it is difficult to test at scale and is not comprehensive. And, if not done right, it also risks being abused itself for tracking because as it generates a list based on your behavior, and your behavior is unique, the list it generates can itself by used as a way to track you. Nevertheless, in-browser tracker identification is complementary to a well-done block list like one derived from Tracker Radar. Of course, we know we aren't perfect either, and Tracker Radar is very much a work in progress. We hope to continue to expand and improve it in the future. How do I get Tracker Radar data? The data is publicly available under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0. International license. The code we use to make the Tracker Radar is open source and available on GitHub under the Apache 2.0 License. We welcome feedback and hope you find these resources useful. If you'd like to license our Tracker Radar data set for commercial use, please reach out. |


