
| Previous
Page |
PCLinuxOS
Magazine |
PCLinuxOS |
Article List |
Disclaimer |
Next Page |
EBCDIC Handling Library: A Ruby Project |
|
by phorneker As long as we are going to be cooped up with the current pandemic, and to keep my sanity going, I decided to revive a software project that was the basis for my development of credit reporting software, the ASCII to EBCDIC translator. As long as I am going to revive this project, I may as well make a library of functions that handle data in EBCDIC with translations to and from ASCII. Of course, I would have to include UTF-8 and UTF-16 as these character codes did not exist back in the 1990s. Why EBCDIC? EBCDIC stands for Extended Binary Coded Decimal Interchange Code and was the official coding used for storing data on IBM mainframes in the late 1950s and 1960s such as the System 360 and System 390. EBCDIC is still in use by IBM's Z-Series mainframes available today. When I was developing credit reporting software in the 1990s, customers could report credit information on diskettes. The file created on diskettes is an emulation of the tape format used for the IBM mainframe applications, the customer did not need to worry about the format of the tape, nor about the encoding of the data for credit reporting. The software I created took care of that detail. Part of the magic behind this encoding is an ASCII to EBCDIC translation library, and that is the subject of this project. Each character is 8 bits long One thing that EBCDIC and ASCII have in common is that each character takes up exactly one byte of storage. But that is where the similarity ends. Standard ASCII is actually seven bits long and has numeric values ranging from 0 to 127 (or 0x00 to 0x7f in hexidecimal). So what happens to the eighth bit? Standard ASCII has no default action for characters containing the eighth bit (hexidecimal values of 0x80 to 0xFF.) In practice, however, the eighth bit is typically used for displaying character graphics, i.e. symbols that are typically used to create things like windows on a text display, or large sized logos. This character set can be found on 8-bit machines like the Commodore PET/VIC-20/64/128, the Atari 8-bit line of machines, and even the IBM-PC models 5150, 5160 and 5170 (commonly known as the IBM-PC, XT and AT) Languages such as Pascal and BASIC allow for display of the characters whose ASCII values range from 128 to 255. For instance typing in this quick and dirty program in Turbo Pascal (for DOS in DOSBOX): 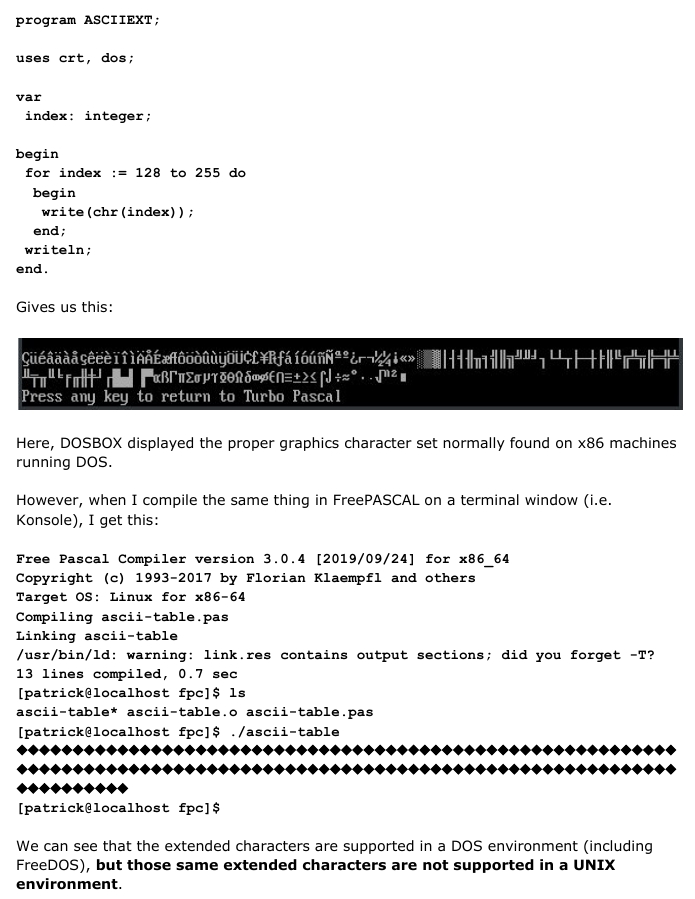 
The remaining end statement is used to indicate the end of the for loop. The trailing puts statement ensures the Ruby program ends output by placing the cursor on the next line ensuring readability of the output, and to make sure the command prompt does not inadvertently become part of the program's output shown below: 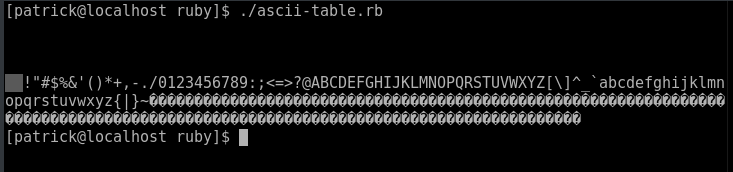 How does Ruby handle EBCDIC? The encode method is normally used to convert between character encodings such as UTF-8 and UTF-16 and plain ASCII. When EBCDIC was developed, Unicode did not exist. Mainframes rather than clouds ruled the computing world. Sony at that time had exited the rice cooker and warmer business, and started manufacturing electronics. Their first home computers would not come into existence until the mid 1980s. As a result, there is no support for the EBCDIC coding of characters. That is where this project comes in. The Differences between EBCDIC and ASCII I have made some observations when comparing the two character sets with values from 0 to 255 (or 0x00 to 0xFF in hexidecimal) Source: http://ascii-table.com/ebcdic-table.php The following character codes are the same in ASCII as it is in EBCDIC, so no translation is needed.
The following EBCDIC codes have different numeric ASCII equivalents: 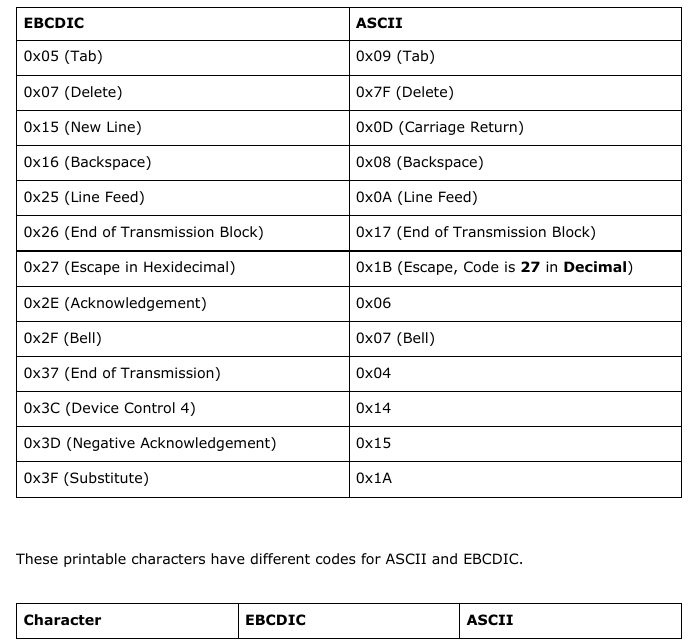 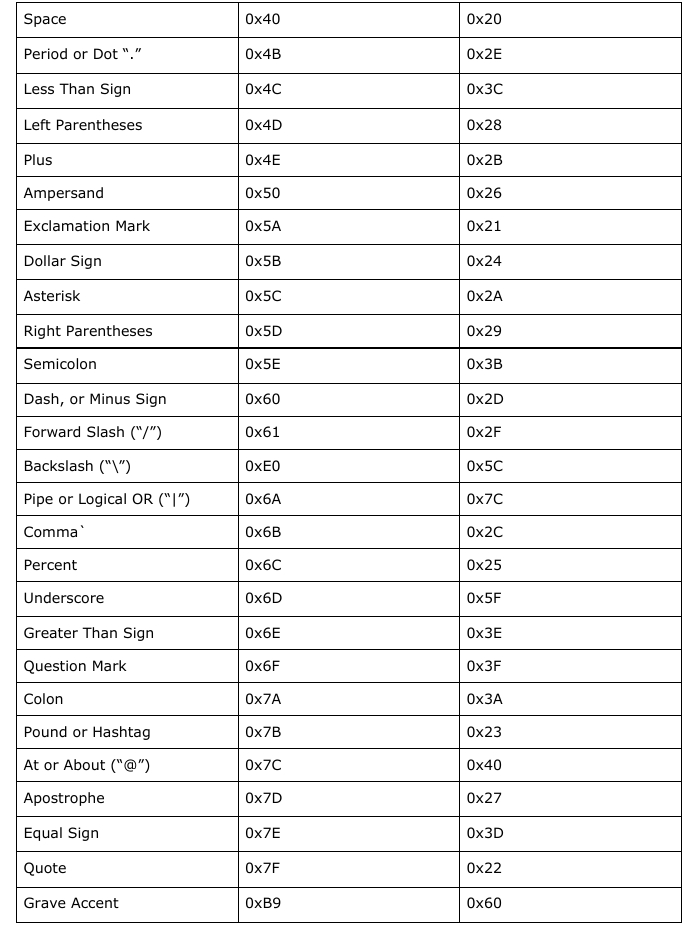 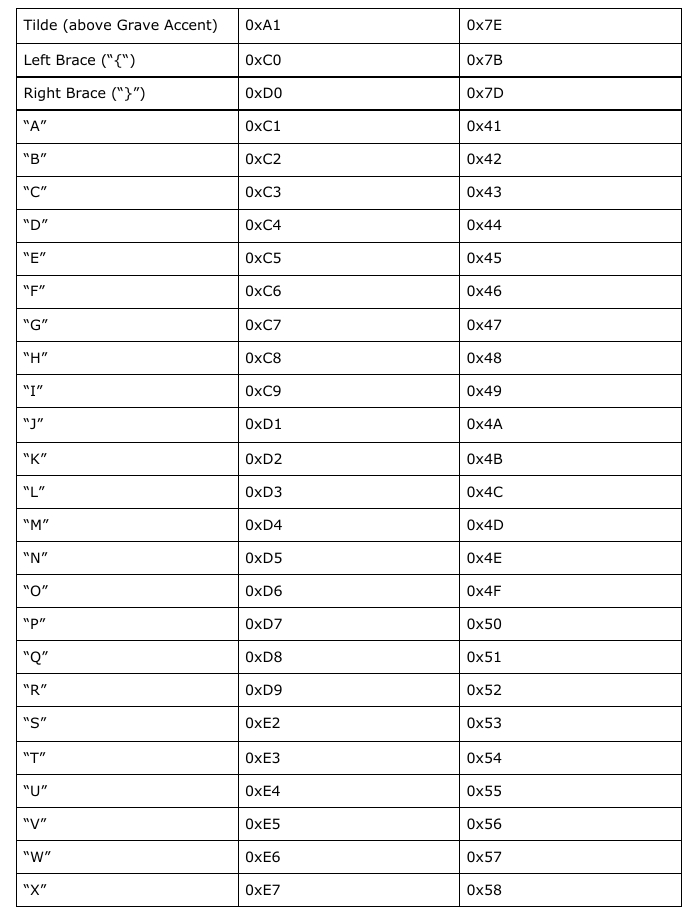 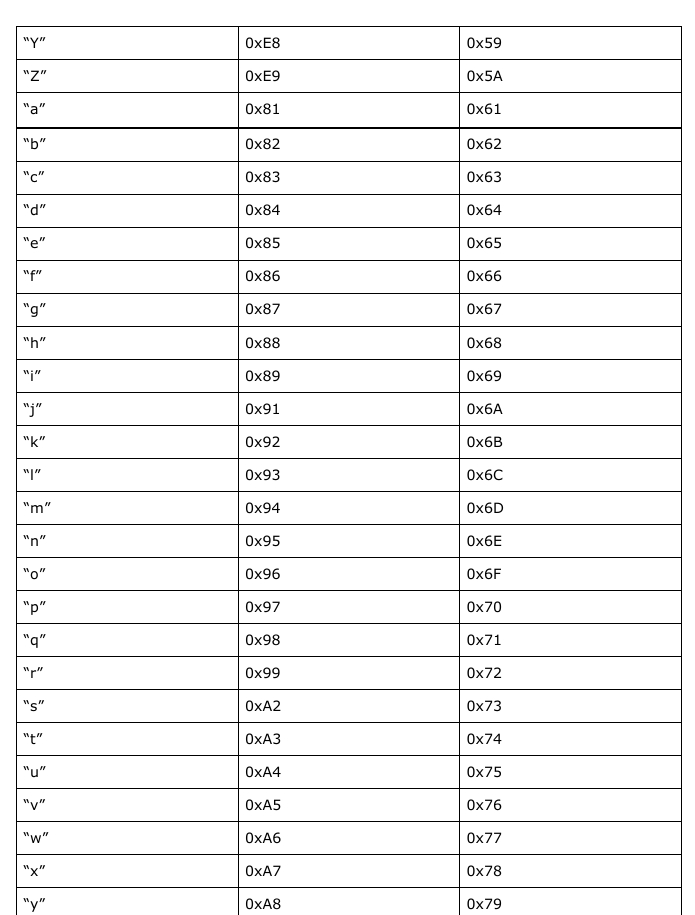 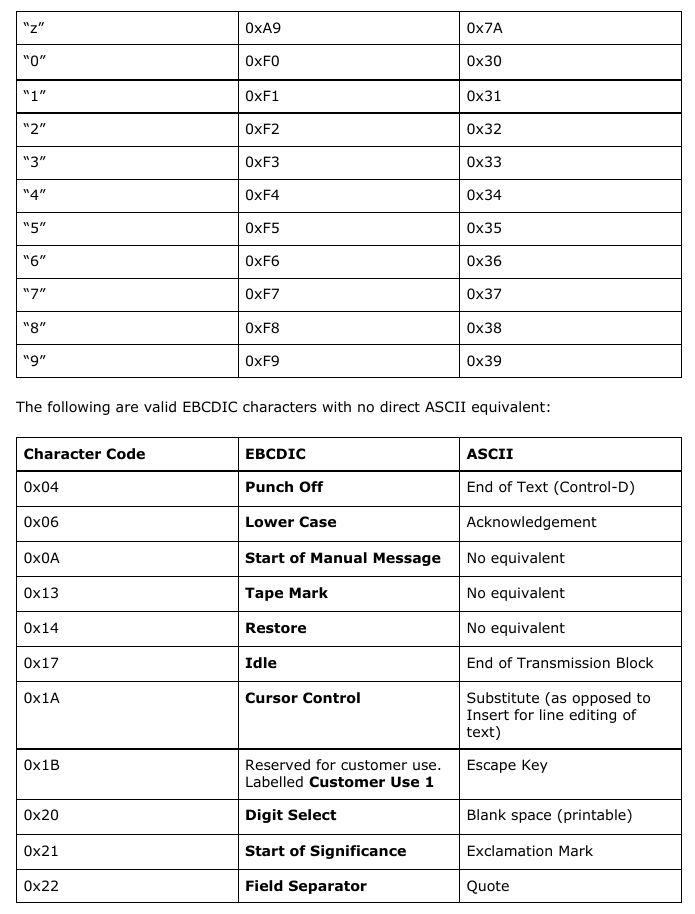 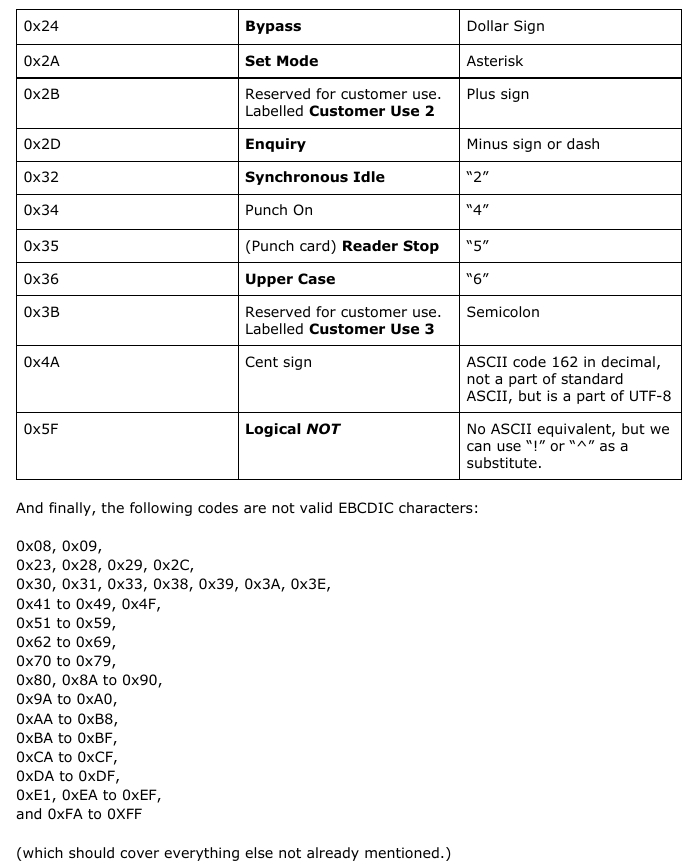 (which should cover everything else not already mentioned.) Planning the Ruby library To build this library, we need to plan what functions will be implemented. The first thing we need to implement are two character translation functions: One to convert ASCII to EBCDIC and the other to convert EBCDIC back to ASCII. Given what I have just shown you in the last section, this is not going to be a simple task. We can implement the functions for all ASCII characters that have EBCDIC equivalents. But, we need to consider that each conversion function will have a separate issues that need to be addressed, the most obvious being what to do about ASCII characters with no EBCDIC equivalents, and whether we should consider using only Standard (7-bit) ASCII or go with a 8-bit ASCII, and if so, what to include in the ASCII extensions. For now, let us stick with the 7-bit ASCII. For these functions, the case statement would be a logical choice, but how big are these statements going to be? Thankfully, the case statement is populated with when statements which can be populated with more than one range per when statement. The else statement serves as a fallback when nothing fits into the structure of the functions we are going to define. Finally, the end statement is used to indicate the end of the function definition. Let us start with the ASCII to EBCDIC function. The naming of functions is important here, so let us choose a name that makes the most sense. We could call this a2e, but the problem here is that when we go back to look at the source some time in the future, we will be asking ourselves, “What does a2e mean?”, and if we decide to name another function with the same two letters, it will cause some confusion. Likewise, we could call this ascii2ebcdic, but while this makes it obvious what the function does, it could prove to not be so productive when it comes to keeping track of the project. Convention tells us to create meaningful names, and abbreviating ASCII and EBCDIC to say asc2ebc makes sense here. It is long enough that we know what asc and ebc mean, but not too long that it becomes unproductive to consistently type in the full words. Also, the chance of typographical errors is reduced when we use abbreviations such as asc and ebc.    When it comes to the actual implementation of the functions, we will have to examine closely the ASCII and EBCDIC tables and attempt to simplify the tables into something that can be easily implemented. I chose Ruby for the language to use as this is the example project I promised you some months ago. This could be implemented in most any language, but since this is a Ruby project, it only makes sense to go with Ruby. Also, the next Christmas release of Ruby will be Version 3.0 of the programming language, of which there are significant changes to how coding is done. Given what is happening in the world right now, I am not so sure the release of Version 3.0 will be on time. But, from what I hear about Version 3.0, the transition from 2.x releases is similar to what happened when Python went from 2.x to 3.x. |


